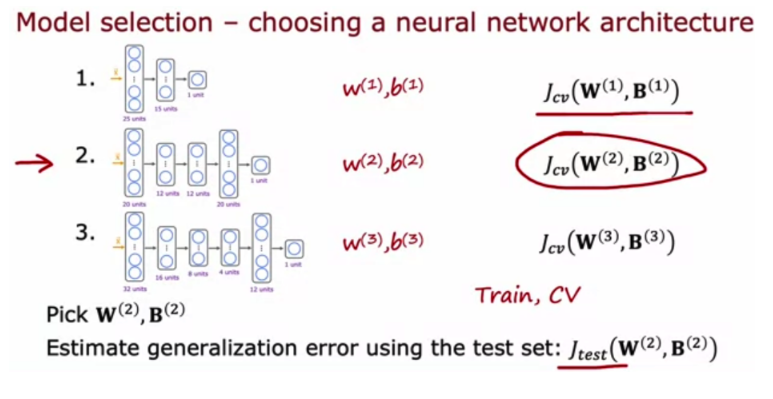
3. For a classification task; suppose you train three different models using three different neural network architectures. Which data do you use to evaluate the three models in order to choose the best one?
See if the cross validation error is high compared to the baseline level of performance
Compare the training error to the cross validation error.
Compare the training error to the baseline level of performance
See if the training error is high (above 15% or so)
6. You find that your algorithm has high bias. Which of these seem like good options for improving the algorithm’s performance? Hint: two of these are correct.
Collect additional features or add polynomial features
Remove examples from the training set
Decrease the regularization parameter λ (lambda)
Collect more training examples
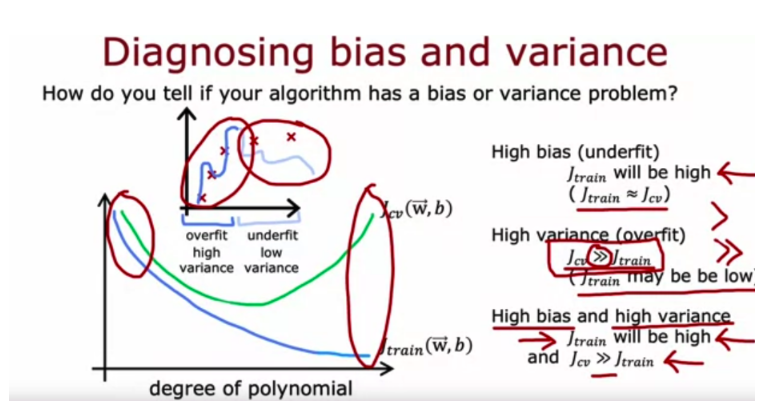
7. You find that your algorithm has a training error of 2%, and a cross validation error of 20% (much higher than the training error). Based on the conclusion you would draw about whether the algorithm has a high bias or high variance problem, which of these seem like good options for improving the algorithm’s performance? Hint: two of these are correct.
Manually examine a sample of the training examples that the model misclassified in order to identify common traits and trends.
Collecting additional training data in order to help the algorithm do better.
Calculating the test error Jtest
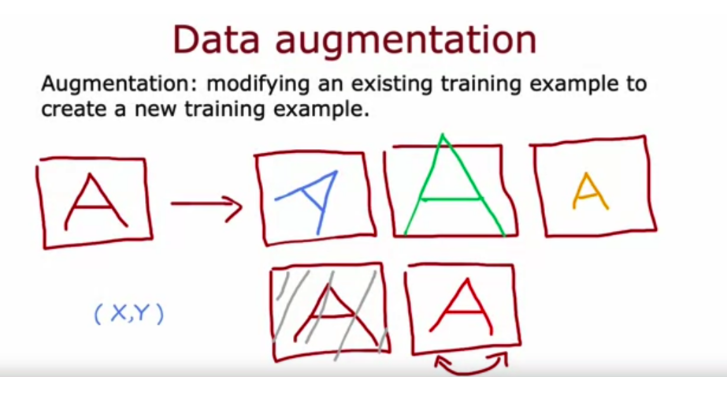
9. We sometimes take an existing training example and modify it (for example, by rotating an image slightly) to create a new example with the same label. What is this process called?