
structuring machine learning projects week 1 quiz
Machine Learning Flight Simulator - Bird Recognition in the City of Peacetopia (Case Study)
1. Problem Statement
This example is adapted from a real production application, but with details disguised to protect confidentiality.

You are a famous researcher in the City of Peacetopia. The people of Peacetopia have a common characteristic: they are afraid of birds. To save them, you have to build an algorithm that will detect any bird flying over Peacetopia and alert the population.
The City Council gives you a dataset of 10,000,000 images of the sky above Peacetopia, taken from the city’s security cameras. They are labeled:
y = 0: There is no bird on the image
y = 1: There is a bird on the image
Your goal is to build an algorithm able to classify new images taken by security cameras from Peacetopia.
There are a lot of decisions to make:
What is the evaluation metric?
How do you structure your data into train/dev/test sets?
Metric of success
The City Council tells you the following that they want an algorithm that
Has high accuracy.
Runs quickly and takes only a short time to classify a new image.
Can fit in a small amount of memory, so that it can run in a small processor that the city will attach to many different security cameras.
You are delighted because this list of criteria will speed development and provide guidance on how to evaluate two different algorithms. True/False?
- True
- False
2. The city asks for your help in further defining the criteria for accuracy, runtime, and memory. How would you suggest they identify the criteria?
- Suggest to them that they define which criterion is most important. Then, set thresholds for the other two.
- Suggest to them that they focus on whichever criterion is important and then eliminate the other two.
- Suggest that they purchase more infrastructure to ensure the model runs quickly and accurately.
3. Which of the following best answers why it is important to identify optimizing and satisficing metrics?
- It isn’t. All metrics must be met for the model to be acceptable.
- Identifying the metric types sets thresholds for satisficing metrics. This provides explicit evaluation criteria.
- Knowing the metrics provides input for efficient project planning.
- Identifying the optimizing metric informs the team which models they should try first.
4. You propose a 95/2.5%/2.5% for train/dev/test splits to the City Council. They ask for your reasoning. Which of the following best justifies your proposal?
- The emphasis on the training set provides the most accurate model, supporting the memory and processing satisficing metrics.
- With a dataset comprising 10M individual samples, 2.5% represents 250k samples, which should be more than enough for dev and testing to evaluate bias and variance.
- The emphasis on the training set will allow us to iterate faster.
- The most important goal is achieving the highest accuracy, and that can be done by allocating the maximum amount of data to the training set.
5. After setting up your train/dev/test sets, the City Council comes across another 1,000,000 images, called the “citizens’ data”. Apparently the citizens of Peacetopia are so scared of birds that they volunteered to take pictures of the sky and label them, thus contributing these additional 1,000,000 images. These images are different from the distribution of images the City Council had originally given you, but you think it could help your algorithm.
Notice that adding this additional data to the training set will make the distribution of the training set different from the distributions of the dev and test sets.
Is the following statement true or false?
"You should not add the citizens' data to the training set, because if the training distribution is different from the dev and test sets, then this will not allow the model to perform well on the test set."
- True
- False
6. One member of the City Council knows a little about machine learning, and thinks you should add the 1,000,000 citizens’ data images to the test set. You object because:
- This would cause the dev and test set distributions to become different. This is a bad idea because you’re not aiming where you want to hit.
- The test set no longer reflects the distribution of data (security cameras) you most care about.
- A bigger test set will slow down the speed of iterating because of the computational expense of evaluating models on the test set.
- The 1,000,000 citizens’ data images do not have a consistent x–>y mapping as the rest of the data.
7. You train a system, and the train/dev set errors are 3.5% and 4.0% respectively. You decide to try regularization to close the train/dev accuracy gap. Do you agree?
- Yes, because this shows your bias is higher than your variance.
- Yes, because having a 4.0% training error shows you have a high bias.
- No, because you do not know what the human performance level is.
- No, because this shows your variance is higher than your bias.
8. You want to define what human-level performance is to the city council. Which of the following is the best answer?
- The average performance of all their ornithologists (0.5%).
- The average of regular citizens of Peacetopia (1.2%).
- The performance of their best ornithologist (0.3%).
- The average of all the numbers above (0.66%).
9. Which of the below shows the optimal order of accuracy from worst to best?
- The learning algorithm’s performance -> human-level performance -> Bayes error.
- The learning algorithm’s performance -> Bayes error -> human-level performance.
- Human-level performance -> the learning algorithm’s performance -> Bayes error.
- Human-level performance -> Bayes error -> the learning algorithm’s performance.
10. You find that a team of ornithologists debating and discussing an image gets an even better 0.1% performance, so you define that as “human-level performance.” After working further on your algorithm, you end up with the following:

Based on the evidence you have, which two of the following four options seem the most promising to try? (Check two options.)
- Try increasing regularization.
- Get a bigger training set to reduce variance.
- Train a bigger model to try to do better on the training set.
- Try decreasing regularization.
11. You also evaluate your model on the test set, and find the following:
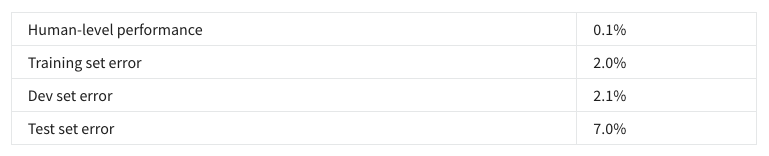
What does this mean? (Check the two best options.)
- You should try to get a bigger dev set.
- You have overfit to the dev set.
- You have underfitted to the dev set.
- You should get a bigger test set.
12. After working on this project for a year, you finally achieve: Human-level performance, 0.10%, Training set error, 0.05%, Dev set error, 0.05%. Which of the following are likely? (Check all that apply.)
- This result is not possible since it should not be possible to surpass human-level performance.
- There is still avoidable bias.
- Pushing to even higher accuracy will be slow because you will not be able to easily identify sources of bias.
- The model has recognized emergent features that humans cannot. (Chess and Go for example)
13. It turns out Peacetopia has hired one of your competitors to build a system as well. Your system and your competitor both deliver systems with about the same running time and memory size. However, your system has higher accuracy! However, when Peacetopia tries out your and your competitor’s systems, they conclude they actually like your competitor’s system better, because even though you have higher overall accuracy, you have more false negatives (failing to raise an alarm when a bird is in the air). What should you do?
- Pick false negative rate as the new metric, and use this new metric to drive all further development.
- Ask your team to take into account both accuracy and false negative rate during development.
- Rethink the appropriate metric for this task, and ask your team to tune to the new metric.
- Look at all the models you’ve developed during the development process and find the one with the lowest false negative error rate.
14. Over the last few months, a new species of bird has been slowly migrating into the area, so the performance of your system slowly degrades because your data is being tested on a new type of data. There are only 1,000 images of the new species. The city expects a better system from you within the next 3 months. Which of these should you do first?
- Add pooling layers to downsample features to accommodate the new species.
- Split them between dev and test and re-tune.
- Augment your data to increase the images of the new bird.
- Put the new species’ images in training data to learn their features
15. The City Council thinks that having more cats in the city would help scare off birds. They are so happy with your work on the Bird detector that they also hire you to build a Cat detector. You have a huge dataset of 100,000,000 cat images. Training on this data takes about two weeks. Which of the statements do you agree with? (Check all that agree.)
- You could consider a tradeoff where you use a subset of the cat data to find reasonable performance with reasonable iteration pacing.
- With the experience gained from the Bird detector you are confident to build a good Cat detector on the first try.
- Given a significant budget for cloud GPUs, you could mitigate the training time.
- Accuracy should exceed the City Council’s requirements but the project may take as long as the bird detector because of the two week training/iteration time.