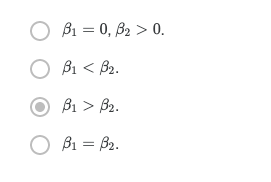Stochastic Gradient Descent, Batch Gradient Descent, and Mini-Batch Gradient Descent all make equal use of vectorization.
Stochastic Gradient Descent
Mini-Batch Gradient Descent with mini-batch size m/ 2
3. We usually choose a mini-batch size greater than 1 and less than
m, because that way we make use of vectorization but not fall into the slower case of batch gradient descent.
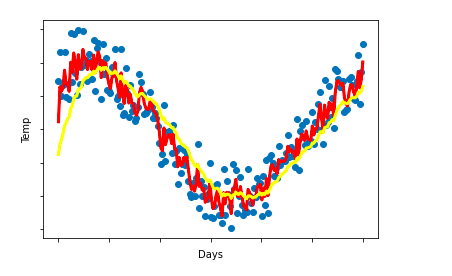
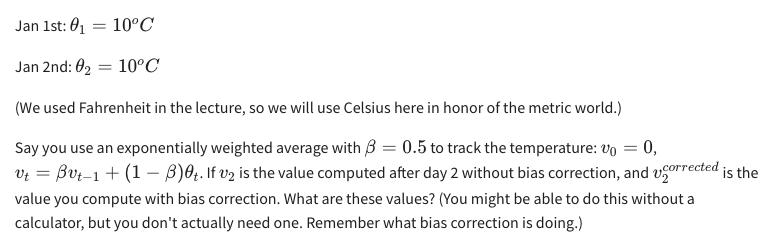
7. You use an exponentially weighted average on the London temperature dataset. You use the following to track the temperature: v
t
=βv
t−1
+(1−β)θ
t
. The yellow and red lines were computed using values
1
β
1
and
2
β
2
respectively. Which of the following are true?
Gradient descent with momentum makes use of moving averages.
Increasing the hyperparameter B smooths out the process of gradient descent
It decreases the learning rate as the number of epochs increases
It generates faster learning by reducing the oscillation of the gradient descent process
9. Suppose batch gradient descent in a deep network is taking excessively long to find a value of the parameters that achieves a small value for the cost function
(
[
1
]
,
[
1
]
,
.
.
.
,
[
]
,
[
]
)
J(W
[1]
,b
[1]
,...,W
[L]
,b
[L]
). Which of the following techniques could help find parameter values that attain a small value for J? (Check all that apply)