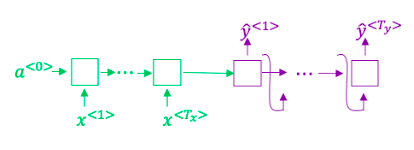
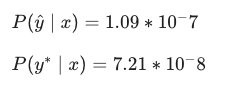1. Consider using this encoder-decoder model for machine translation.
True/False: This model is a “conditional language model” in the sense that the decoder portion (shown in purple) is modeling the probability of the output sentence y given the input sentence x.
Beam search will generally find better solutions (i.e. do a better job maximizing P(y | 2)
3. True/False: In machine translation, if we carry out beam search without using sentence normalization, the algorithm will tend to output overly long translations.
4. Suppose you are building a speech recognition system, which uses an RNN model to map from audio clip 2 to a text transcript y. Your algorithm uses beam search to try to find the value of y that maximizes P(y | x).
On a dev set example, given an input audio clip, your algorithm outputs the transcript 2 = "I'm building an A Eye system in Silly con Valley.", whereas a human gives a much superior transcript y* = "I'm building an Al system in Silicon Valley."
According to your model,
Would you expect increasing the beam width B to help correct this example?
5. Continuing the example from Q4, suppose you work on your algorithm for a few more weeks, and now find that for the vast majority of examples on which your algorithm makes a mistake, P(y*|x) > P(y^|x). ∣x). This suggests you should not focus your attention on improving the search algorithm.
7. The network learns where to “pay attention” by learning the values e^, which are computed using a small neural network:
We can't replace s^ with s^ as an input to this neural network. This is because s^ depends on a^ which in turn depends on e^; so at the time we need to evaluate this network, we haven’t computed s^ yet.
8. Compared to the encoder-decoder model shown in Question 1 of this quiz (which does not use an attention mechanism), we expect the attention model to have the least advantage when:
9. Under the CTC model, identical repeated characters not separated by the “blank” character (_) are collapsed. Under the CTC model, what does the following string collapse to?