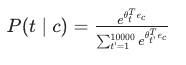Quiz - Natural Language Processing & Word Embeddings
1. Suppose you learn a word embedding for a vocabulary of 10000 words. Then the embedding vectors could be 10000 dimensional, so as to capture the full range of variation and meaning in those words.
A supervised learning algorithm for learning word embeddings
A linear transformation that allows us to solve analogies on word vectors
A non-linear dimensionality reduction technique
An open-source sequence modeling library
3. Suppose you download a pre-trained word embedding which has been trained on a huge corpus of text. You then use this word embedding to train an RNN for a language task of recognizing if someone is happy from a short snippet of text, using a small training set.
True/False: Then even if the word “upset” does not appear in your small training set, your RNN might reasonably be expected to recognize “I’m upset” as deserving a label y = 0.
5. Let A be an embedding matrix, and let 04567 be a one-hot vector corresponding to word 4567. Then to get the embedding of word 4567, why don't we call A * 04567 in Python?
7. In the word2vec algorithm, you estimate P(t | c), where t is the target word and c is a context word. How are t and c chosen from the training set? Pick the best answer.
10. You have trained word embeddings using a text dataset of m1 words. You are considering using these word embeddings for a language task, for which you have a separate labeled dataset of my words. Keeping in mind that using word embeddings is a form of transfer learning, under which of these circumstances would you expect the word embeddings to be helpful?