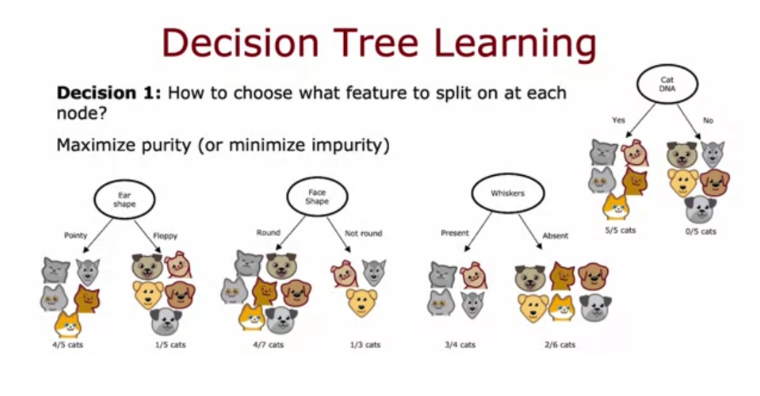
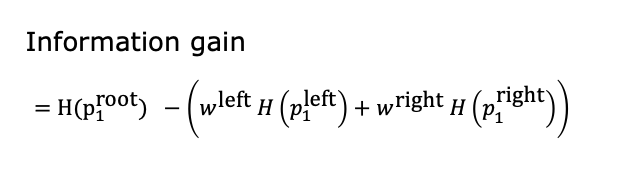1. Based on the decision tree shown in the lecture, if an animal has floppy ears, a round face shape and has whiskers, does the model predict that it's a cat or not a cat?
2. Take a decision tree learning to classify between spam and non-spam email. There are 20 training examples at the root note, comprising 10 spam and 10 non-spam emails. If the algorithm can choose from among four features, resulting in four corresponding splits, which would it choose (i.e., which has highest purity)?
Left split: 10 of 10 emails are spam. Right split: 0 of 10 emails are spam.
Left split: 7 of 8 emails are spam. Right split: 3 of 12 emails are spam.
Left split: 2 of 2 emails are spam. Right split: 8 of 18 emails are spam.
Left split: 5 of 10 emails are spam. Right split: 5 of 10 emails are spam.
Practice quiz: Decision tree learning
3. Recall that entropy was defined in lecture as H(p_1) = - p_1 log_2(p_1) - p_0 log_2(p_0), where p_1 is the fraction of positive examples and p_0 the fraction of negative examples.
At a given node of a decision tree, , 6 of 10 examples are cats and 4 of 10 are not cats. Which expression calculates the entropy H(p1) of this group of 10 animals?
4. Recall that information was defined as follows: H(p
1
root
)−(w
left
H(p
1
left
)+w
right
H(p
1
right
))
Before a split, the entropy of a group of 5 cats and 5 non-cats is 5
/
10
)
H(5/10). After splitting on a particular feature, a group of 7 animals (4 of which are cats) has an entropy of
H(4/7). The other group of 3 animals (1 is a cat) and has an entropy of H(1/3). What is the expression for information gain?
5. To represent 3 possible values for the ear shape, you can define 3 features for ear shape: pointy ears, floppy ears, oval ears. For an animal whose ears are not pointy, not floppy, but are oval, how can you represent this information as a feature vector?
6. For a continuous valued feature (such as weight of the animal), there are 10 animals in the dataset. According to the lecture, what is the recommended way to find the best split for that feature?
Use a one-hot encoding to turn the feature into a discrete feature vector of 0’s and 1’s, then apply the algorithm we had discussed for discrete features.
Try every value spaced at regular intervals (e.g., 8, 8.5, 9, 9.5, 10, etc.) and find the split that gives the highest information gain.
Choose the 9 mid-points between the 10 examples as possible splits, and find the split that gives the highest information gain.
Use gradient descent to find the value of the split threshold that gives the highest information gain.
7. Which of these are commonly used criteria to decide to stop splitting? (Choose two.)
Train the algorithm multiple times on the same training set. This will naturally result in different trees.
A: Sample the training data with replacement and select a random subset of features to build each tree
If you are training B trees, train each one on 1/B of the training set, so each tree is trained on a distinct set of examples.
Sample the training data without replacement
9. You are choosing between a decision tree and a neural network for a classification task where the input x is a 100x100 resolution image. Which would you choose?