
structuring machine learning projects week 2 quiz
Machine Learning Flight Simulator - Autonomous Driving (Case Study)
1. To help you practice strategies for machine learning, this week we’ll present another scenario and ask how you would act. We think this “simulator” of working in a machine learning project will give a task of what leading a machine learning project could be like!
You are employed by a startup building self-driving cars. You are in charge of detecting road signs (stop sign, pedestrian crossing sign, construction ahead sign) and traffic signals (red and green lights) in images. The goal is to recognize which of these objects appear in each image. As an example, the above image contains a pedestrian crossing sign and red traffic lights
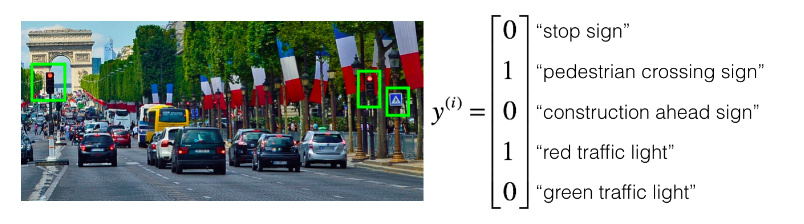
Your 100,000 labeled images are taken using the front-facing camera of your car. This is also the distribution of data you care most about doing well on. You think you might be able to get a much larger dataset off the internet, that could be helpful for training even if the distribution of internet data is not the same.
You are just getting started on this project. What is the first thing you do? Assume each of the steps below would take about an equal amount of time (a few days).
- Spend a few days collecting more data using the front-facing camera of your car, to better understand how much data per unit time you can collect.
- Spend a few days training a basic model and see what mistakes it makes.
- Spend a few days checking what is human-level performance for these tasks so that you can get an accurate estimate of Bayes error.
- Spend a few days getting the internet data, so that you understand better what data is available.
2. Your goal is to detect road signs (stop sign, pedestrian crossing sign, construction ahead sign) and traffic signals (red and green lights) in images. The goal is to recognize which of these objects appear in each image. You plan to use a deep neural network with ReLU units in the hidden layers. For the output layer, a softmax activation would be a good choice for the output layer because this is a multi-task learning problem. True/False?
- True
- False
3. You are carrying out error analysis and counting up what errors the algorithm makes. Which of these datasets do you think you should manually go through and carefully examine, one image at a time?
- 500 randomly chosen images
- 10,000 images on which the algorithm made a mistake
- 500 images on which the algorithm made a mistake
- 10.000 randomly chosen images
4. After working on the data for several weeks, your team ends up with the following data: 100,000 labeled images taken using the front-facing camera of your car. 900,000 labeled images of roads downloaded from the internet. Each image’s labels precisely indicate the presence of any specific road signs and traffic signals or combinations of them. For example, y^(i) ( ) = [ 1 0 0 1 0 ] y (i) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 0 0 1 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ means the image contains a stop sign and a red traffic light. Because this is a multi-task learning problem, when an image is not fully labeled (for example: ( 0 ? ? 1 0 ) ⎝ ⎜ ⎜ ⎜ ⎜ ⎜ ⎛ 0 ? ? 1 0 ⎠ ⎟ ⎟ ⎟ ⎟ ⎟ ⎞ ) we can use it if we ignore those entries when calculating the loss function. True/False?
- False
- True
5. The distribution of data you care about contains images from your car’s front-facing camera, which comes from a different distribution than the images you were able to find and download off the internet. The best way to split the data is using the 900,000 internet images to train, and divide the 100,000 images from your car's front-facing camera between dev and test sets. True/False?
- True
- False
6. Assume you’ve finally chosen the following split between the data:

You also know that human-level error on the road sign and traffic signals classification task is around 0.5%. Which of the following is true?
- You have a high bias.
- You have a high variance problem.
- The size of the train-dev set is too high.
- You have a large data-mismatch problem.
7. Assume you’ve finally chosen the following split between the data:

You also know that human-level error on the road sign and traffic signals classification task is around 0.5%. Based on the information given, a friend thinks that the training data distribution is much harder than the dev/test distribution. What do you think?
- Your friend is wrong. (i.e., Bayes error for the dev/test distribution Is probably higher than for the train distribution.)
- Your friend is probably right. (i.e., Bayes error for the dev/test distribution is probably lower than for the train distribution.)
- There’s insufficient information to tell if your friend is right or wrong.
8. You decide to focus on the dev set and check by hand what the errors are due to. Here is a table summarizing your discoveries:

In this table, 4.1%, 8.2%, etc. are a fraction of the total dev set (not just examples of your algorithm mislabeled). For example, about 8.2/15.3 = 54% of your errors are due to partially occluded elements in the image.
Which of the following is the correct analysis to determine what to prioritize next?
- You should weigh how costly it would be to get more images with partially occluded elements, to decide if the team should work on it or not.
- You should prioritize getting more foggy pictures since that will be easier to solve.
- Since 8.2>4.1 + 2.0+1.0, the priority should be to get more images with partially occluded elements.
- Since there is a high number of incorrectly labeled data in the dev set, you should prioritize fixing the labels on the whole training set.
9. You can buy a specially designed windshield wiper that helps wipe off some of the raindrops on the front-facing camera.

Which of the following statements do you agree with?
- 2.2% would be a reasonable estimate of the maximum amount this windshield wiper could improve performance.
- 2.2% would be a reasonable estimate of the minimum amount this windshield wiper could improve performance.
- 2.2% would be a reasonable estimate of how much this windshield wiper could worsen performance in the worst case.
- 2.2% would be a reasonable estimate of how much this windshield wiper will improve performance.
10. You decide to use data augmentation to address foggy images. You find 1,000 pictures of fog off the internet, and “add” them to clean images to synthesize foggy days, like this:

Which of the following statements do you agree with?
- So long as the synthesized fog looks realistic to the human eye, you can be confident that the synthesized data is accurately capturing the distribution of real foggy images (or a subset of it), since human vision is very accurate for the problem you’re solving.
- There is little risk of overfitting to the 1.000 pictures of fog so long as you are combining it with a much larger (>>1.000) set of clean/non-foggy images.
- Adding synthesized images that look like real foggy pictures taken from the front-facing camera of your car to the training dataset won’t help the model improve because it will introduce avoidable bias.
11. After working further on the problem, you've decided to correct the incorrectly labeled data. Your team corrects the labels of the wrongly predicted images on the dev set.
You have to correct the labels of the test so test and dev sets have the same distribution, but you won't change the labels on the train set because most models are robust enough they don't get severely affected by the difference in distributions. True/False?
- False, the test set shouldn’t be changed since we want to know how the model performs in real data.
- True, as pointed out, we must keep dev and test with the same distribution. And the labels at training should be fixed only in case of a systematic error.
- False, the test set should be changed, but also the train set to keep the same distrubution between the train, dev and test sets.
12. Your client asks you to add the capability to detect dogs that may be crossing the road to the system. He can provide a relatively small set containing dogs. Which of the following do you agree most with?
- You will have to re-train the whole model now including the dog’s data.
- You can use weight pre-trained on the original data, and fine-tune with the data now including the dogs.
- Using pre-trained weights can severely hinder the ability of the model to detect dogs since they have too many learned features.
13. One of your colleagues at the startup is starting a project to classify stop signs in the road as speed limit signs or not. He has approximately 30,000 examples of each image and 30,000 images without a sign. He thought of using your model and applying transfer learning but then he noticed that you use multi-task learning, hence he can't use your model. True/False?
- True
- False
14. To recognize a stop sign you use the following approach: First, we localize any traffic sign in an image. After that, we determine if the sign is a stop sign or not. We are using multi-task learning. True/False?
- True
- False
15. An end-to-end approach doesn't require that we hand-design useful features, it only requires a large enough model. True/False?
- True
- False